
In questo articolo vediamo un ripasso guidato dell’esame per la certificazione Databricks Spark Associate Developer con Scala.
Gli argomenti da conoscere per l’esame di certificazione CRT020 – Spark certified associated developerwith Scala sono quelli riportati alla pagina linkata.
In questo articolo vedremo soltanto le parti di programmazione dell’esame di certificazione.
Nei riquadri colorati ho riportato il testo come dal sito Databricks
SparkContext
Candidates are expected to know how to use the SparkContext to control basic configuration settings such as spark.sql.shuffle.partitions.
Innanzitutto verifichiamo che versione di Spark stiamo usando:
spark.version
res1: String = 2.4.4
Per settare i parametri di configurazione di Apache Spark posso usare il metodo spark.conf.set direttamente nella Spark-shell (o in Zeppelin)
spark.conf.set("spark.sql.shuffle.partitions", 6)
spark.conf.set("spark.executor.memory", "6g")
per verificare che i parametri siano stati settati correttamente uso il metodo spark.conf.get
print(spark.conf.get("spark.sql.shuffle.partitions") + ", " + spark.conf.get("spark.executor.memory"))
6, 6g
Per visualizzare tutti i settaggi posso usare spark.conf.getAll
spark.conf.getAll.foreach(println)
(zeppelin.pyspark.python,C:\Users\home\Anaconda3\envs\conda2020\python) (spark.driver.host,10.0.75.1) (zeppelin.dep.localrepo,local−repo) (zeppelin.spark.sql.stacktrace,false) (spark.driver.port,51622) (master,local[15]) (spark.repl.class.uri,spark://10.0.75.1:51622/classes) (zeppelin.spark.useHiveContext,true) (spark.repl.class.outputDir,C:\Users\home\AppData\Local\Temp\spark6251788337677085436) (zeppelin.spark.sql.interpolation,false) (zeppelin.spark.importImplicit,true) (zeppelin.interpreter.output.limit,102400) (spark.app.name,Zeppelin) (zeppelin.R.cmd,R) (zeppelin.spark.maxResult,1000) (zeppelin.pyspark.useIPython,true) (zeppelin.spark.concurrentSQL,false) (zeppelin.spark.enableSupportedVersionCheck,true) (zeppelin.spark.printREPLOutput,true) (zeppelin.dep.additionalRemoteRepository,spark−packages,http://dl.bintray.com/spark−packages/maven,false;) (org.apache.spark.storage.BlockManager,DEBUG) (spark.executor.id,driver) (log4j.logger.org.apache.spark.storage.BlockManager,TRACE) (zeppelin.spark.useNew,true) (spark.useHiveContext,true) (spark.master,local) (zeppelin.R.image.width,100%) (zeppelin.spark.ui.hidden,false) (zeppelin.interpreter.localRepo,C:\zeppelin−0.8.2−bin−all/local−repo/spark) (spark.executor.memory,6g) (spark.driver.allowMultipleContexts,false) (zeppelin.R.render.options,out.format = 'html', comment = NA, echo = FALSE, results = 'asis', message = F, warning = F, fig.retina = 2) (zeppelin.interpreter.max.poolsize,10) (spark.app.id,local−1578911285841) (zeppelin.R.knitr,true) (spark.sql.shuffle.partitions,6)
Prima di definire un nuovo SparkContext devo cancellare quello vecchio
sc.stop()
Per definire i parametri di configurazione posso usare spark.conf (come fatto sopra) oppure l’oggetto SparkConf di org.apache.spark.SparkConf, i due sono equivalenti
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
val conf = new SparkConf().setMaster("local[*]").setAppName("provaApp")
val sc = new SparkContext(conf)
import org.apache.spark.SparkConf import org.apache.spark.SparkContext conf: org.apache.spark.SparkConf = org.apache.spark.SparkConf@13115401 sc: org.apache.spark.SparkContext = org.apache.spark.SparkContext@5a7f8768
Un altro modo per visualizzare i settaggi è usare toDebugString
conf.toDebugString
res4: String = spark.app.name=provaApp spark.driver.extraClassPath=C:\Users\home\Downloads\jar_files\mongo−spark−connector_2.12−2.4.1.jar spark.driver.extraJavaOptions= −Dfile.encoding=UTF−8 −Dzeppelin.log.file='C:\zeppelin−0.8.2−bin−all\logs\zeppelin−interpreter−spark−home−DESKTOP−46GRV54.log' spark.driver.memory=8g spark.executor.extraClassPath=C:\Users\home\Downloads\jar_files\mongo−spark−connector_2.12−2.4.1.jar spark.executor.memory=8g spark.jars=file:///C:/zeppelin−0.8.2−bin−all/interpreter/spark/spark−interpreter−0.8.2.jar,file:/C:/zeppelin−0.8.2−bin−all/interpreter/spark/spark−interpreter−0.8.2.jar spark.master=local[*] spark.repl.local.jars=file:///C:/zeppelin−0.8.2−bin−all/interpreter/spark/spark−interpreter−0.8.2.jar spark.submit.deployMode=client
SparkSession
Sopra abbiamo visto come configurare lo SparkContext, se invece vogliamo definire le proprietà della SparkSession, punto di accesso al cluster di default a partire da Spark 2.0, posso usare il modo che segue.
spark.stop()
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
val conf = new SparkConf().setMaster("local[*]").set("spark.driver.cores", "1").set("spark.executor.memory","4G")
val spark = SparkSession.builder.config(conf=conf).getOrCreate()
import org.apache.spark.SparkConf import org.apache.spark.sql.SparkSession conf: org.apache.spark.SparkConf = org.apache.spark.SparkConf@650f29a4 spark: org.apache.spark.sql.SparkSession = org.apache.spark.sql.SparkSession@7db780c
Nel definire la SparkSession (o lo SparkContext) ci sono due settaggi che sono obbligatori: spark.master e spark.app.name.
Alcuni parametri dello SparkConf (vedi link per la lista completa):
| property name | default | meaning |
|---|---|---|
| spark.app.name | none | |
| spark.driver.cores | 1 | Number of cores to use for the driver process, #only in cluster mode. |
| spark.driver.memory | 1g | |
| spark.executor.memory | 1g | |
| spark.local.dir | /tmp | Directory to use for “scratch” space in Spark, including map output files and RDDs that get stored on disk. |
| spark.master | none | The deploy mode of Spark driver program, either “client” or “cluster”, Which means to launch driver program locally (“client”) or remotely (“cluster”) on one of the nodes inside the cluster. |
DataFrames API
Candidates are expected to know how to:
- Create a DataFrame/Dataset from a collection (e.g. list or set)
Per la creazione di un DataFrame si può vedere questo post.
I punti principali sono riportati sotto.
Creazione di un dataframe – Metodo 1
Per creare un dataframe da una lista di valori si può usare il metodo toDF.
In alcuni casi occorre importare spark.implicits._ per poter fare la conversione da lista a datafame.
import spark.implicits._ val lista_numeri = List(1,2,3,4,5,6,7) val list_df = lista_numeri.toDF()
import spark.implicits._ lista_numeri: List[Int] = List(1, 2, 3, 4, 5, 6, 7) list_df: org.apache.spark.sql.DataFrame = [value: int]
Creazione di un dataframe – Metodo 2
Uso il metodo di Sparksession createDataFrame() definito come:def createDataFrame(rows: rdd[Row], schema: StructType): DataFrame
Il metodo necessita due parametri: un RDD di Row e uno schema definito con StructType.
Lo schema è definito così:
StructType(
List ( StructField("name1", TypeName1), StructField("name2", TypeName2) ...)
)
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.{StructField, StructType, IntegerType, StringType}
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.master("local[15]").appName("test").getOrCreate()
//creiamo un RDD da una sequenza
val someData = spark.sparkContext.parallelize( Seq(
Row(10230, "Paolo"),
Row(12025, "Pippo"),
Row(25876, "Pedro")
)
)
//definiamo lo schema
val someSchema = StructType ( List(
StructField("Identificativo", IntegerType, true),
StructField("Nome", StringType, true)
)
)
//dobbiamo dare come parametri un RDD (creato con sc.parallelize) e lo schema
val someDF = spark.createDataFrame( someData, someSchema )
someDF.show()
+−−−−−−−−−−−−−−+−−−−−+
|Identificativo| Nome|
+−−−−−−−−−−−−−−+−−−−−+
| 10230|Paolo|
| 12025|Pippo|
| 25876|Pedro|
+−−−−−−−−−−−−−−+−−−−−+
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.{StructField, StructType, IntegerType, StringType}
someData: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = ParallelCollectionRDD[0] at parallelize at <console>:37
someSchema: org.apache.spark.sql.types.StructType = StructType(StructField(Identificativo,IntegerType,true), StructField(Nome,StringType,true))
someDF: org.apache.spark.sql.DataFrame = [Identificativo: int, Nome: string]
Un altro modo di usare StructType per definire lo schema del dataframe è il seguente:
import org.apache.spark.sql.types.StructType
val schema = new StructType()
.add($"Identificativo".long.copy(nullable = false))
.add($"Nome".string)
.add($"Cognome".string)
schema.printTreeString
import org.apache.spark.sql.DataFrameReader
val r: DataFrameReader = spark.read.schema(schema)
root |−− Identificativo: long (nullable = false) |−− Nome: string (nullable = true) |−− Cognome: string (nullable = true) import org.apache.spark.sql.types.StructType schema: org.apache.spark.sql.types.StructType = StructType(StructField(Identificativo,LongType,false), StructField(Nome,StringType,true), StructField(Cognome,StringType,true)) import org.apache.spark.sql.DataFrameReader r: org.apache.spark.sql.DataFrameReader = org.apache.spark.sql.DataFrameReader@3e061032
Adesso ho un DataFrameReader che posso usare per leggere i miei file
val data_from_csv = r.csv("exampl1.csv")
//oppure
val data_from_load = r.load("exampl1.csv")
data_from_csv: org.apache.spark.sql.DataFrame = [Identificativo: bigint, Nome: string ... 1 more field] data_from_load: org.apache.spark.sql.DataFrame = [Identificativo: bigint, Nome: string ... 1 more field]
- creare un dataframe da un Map
In questo caso lo schema viene settato automaticamente da Spark.
Con un dato di partenza in formato Map lo schema è:
Map -> Seq -> RDD -> DataFrame
val df = spark.createDataFrame( sc.parallelize( Map(("x", 24), ("y", 25), ("z", 26)).toSeq ) )
df.withColumnRenamed("_1", "nome").withColumnRenamed("_2", "età").show()
+−−−−+−−−+ |nome|età| +−−−−+−−−+ | x| 24| | y| 25| | z| 26| +−−−−+−−−+ df: org.apache.spark.sql.DataFrame = [_1: string, _2: int]
in alternativa si possono usare i metodi toSeq e toDF in cascata (si ricordi di importare spark.implicits._ prima)
import spark.implicits._
Map(("x", 24), ("y", 25), ("z", 26)).toSeq.toDF
import spark.implicits._ res8: org.apache.spark.sql.DataFrame = [_1: string, _2: int]
- Create a DataFrame for a range of numbers
Anche in questo caso ci sono diversi modi per creare un dataframe con un range di numeri.
Nel primo modo si può creare un range, convertirlo in RDD e successivamente usare .toDF()
sc.parallelize(1 to 10).toDF()
res16: org.apache.spark.sql.DataFrame = [value: int]
oppure senza passare da un rdd
import org.apache.spark.sql.DataFrame val ar = 1 to 10 val df: DataFrame = ar.toDF()
import org.apache.spark.sql.DataFrame ar: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) df: org.apache.spark.sql.DataFrame = [value: int]
infine si può usare la funzione spark.range()
spark.range(1, 1000).show(5)
+−−−+ | id| +−−−+ | 1| | 2| | 3| | 4| | 5| +−−−+ only showing top 5 rows
a rigore questo crea un dataset, ma posso usare semplicemente .toDF per trasformarlo in dataframe
spark.range(1,100).toDF("ID").show(5)
+−−−+ | ID| +−−−+ | 1| | 2| | 3| | 4| | 5| +−−−+ only showing top 5 rows
- Access the DataFrameReaders
Il DataFrameReaders da accesso ad una serie di metodi che consentono di leggere i files contenenti i dati.
Posso creare il DataFrameReader esplicitamente con:
import org.apache.spark.sql.DataFrameReader
val r: DataFrameReader = spark.read
r.csv("exampl1.csv")
import org.apache.spark.sql.DataFrameReader r: org.apache.spark.sql.DataFrameReader = org.apache.spark.sql.DataFrameReader@3f709ba res24: org.apache.spark.sql.DataFrame = [_c0: string, _c1: string]
oppure implicitamente senza passare da un oggetto DataFrameReader, ma usando spark.read.csv()
val df = spark.read.csv("exampl1.csv")
df: org.apache.spark.sql.DataFrame = [_c0: string, _c1: string]
Vediamo un esempio preso da The Internal of Spark
val csvLine = "0,Warsaw,Poland"
import org.apache.spark.sql.Dataset
val cities: Dataset[String] = Seq(csvLine).toDS
cities.show
// Define schema explicitly (as below)
// or
// option("header", true) + option("inferSchema", true)
import org.apache.spark.sql.types.StructType
val schema = new StructType()
.add($"id".long.copy(nullable = false))
.add($"city".string)
.add($"country".string)
schema.printTreeString
import org.apache.spark.sql.DataFrame
val citiesDF: DataFrame = spark
.read
.schema(schema)
.csv(cities)
citiesDF.show
+−−−−−−−−−−−−−−−+ | value| +−−−−−−−−−−−−−−−+ |0,Warsaw,Poland| +−−−−−−−−−−−−−−−+ root |−− id: long (nullable = false) |−− city: string (nullable = true) |−− country: string (nullable = true) +−−−+−−−−−−+−−−−−−−+ | id| city|country| +−−−+−−−−−−+−−−−−−−+ | 0|Warsaw| Poland| +−−−+−−−−−−+−−−−−−−+ csvLine: String = 0,Warsaw,Poland import org.apache.spark.sql.Dataset cities: org.apache.spark.sql.Dataset[String] = [value: string] import org.apache.spark.sql.types.StructType schema: org.apache.spark.sql.types.StructType = StructType(StructField(id,LongType,false), StructField(city,StringType,true), StructField(country,StringType,true)) import org.apache.spark.sql.DataFrame citiesDF: org.apache.spark.sql.DataFrame = [id: bigint, city: string ... 1 more field]
- Register User Defined Functions (UDFs)
Dobbiamo registrare una funzione da noi definita (UDF), che potremo poi usare per operare sui dataframe o in una espressione SQL.
Usiamo il metodo udf(), con parametro la funzione da registrare. Nel nostro caso la funzione da registrare è:x(Double) => {x*x*x}
In questo modo registriamo la UDF per l’utilizzo nella dataFrame API. Si badi che non possiamo ancora usare la funzione nelle espressioni SQL.
//importiamo udf import org.apache.spark.sql.functions.udf val power3udf = udf( (x:Double) => ( x*x*x ) ) val df = spark.sparkContext.parallelize(0 to 10 by 2).toDF() df.show() df.select(power3udf( $"value" )).show()
+−−−−−+ |value| +−−−−−+ | 0| | 2| | 4| | 6| | 8| | 10| +−−−−−+ +−−−−−−−−−−+ |UDF(value)| +−−−−−−−−−−+ | 0.0| | 8.0| | 64.0| | 216.0| | 512.0| | 1000.0| +−−−−−−−−−−+ import org.apache.spark.sql.functions.udf power3udf: org.apache.spark.sql.expressions.UserDefinedFunction = UserDefinedFunction(<function1>,DoubleType,Some(List(DoubleType))) df: org.apache.spark.sql.DataFrame = [value: int]
Di seguito un altro esempio di registrazione di una UDF, l’esempio è preso dall’articolo di Medium Spark User Defined Functions (UDFs).
Nell’esempio ho una funzione che converte le stringhe di input in minuscolo e rimuove tutti gli spazi.
import org.apache.spark.sql.types.StringType
def lowerRemoveAllWhitespace(s: String): String = {
s.toLowerCase().replaceAll("\\s", "")
}
val lowerRemoveAllWhitespaceUDF = udf[String, String](lowerRemoveAllWhitespace)
val sourceDF = List(
(" HI THERE "),
(" GivE mE PresenTS ")).toDF()
sourceDF.show()
sourceDF.select(
lowerRemoveAllWhitespaceUDF(col("value")).as("clean_value")
).show()
+−−−−−−−−−−−−−−−−−−−−+ | value| +−−−−−−−−−−−−−−−−−−−−+ | HI THERE | | GivE mE PresenTS...| +−−−−−−−−−−−−−−−−−−−−+ +−−−−−−−−−−−−−−+ | clean_value| +−−−−−−−−−−−−−−+ | hithere| |givemepresents| +−−−−−−−−−−−−−−+ import org.apache.spark.sql.types.StringType lowerRemoveAllWhitespace: (s: String)String lowerRemoveAllWhitespaceUDF: org.apache.spark.sql.expressions.UserDefinedFunction = UserDefinedFunction(<function1>,StringType,Some(List(StringType))) sourceDF: org.apache.spark.sql.DataFrame = [value: string]
La funzione è registrata in dataframe. Non ci resta che registrarla anche in SQL.
//creiamo un dataframe
val df = (1 to 100 by 3).toDF("num")
df.show(5)
//registrimo la funzione in SQL
spark.udf.register("power2", (x: Double) => x*x)
//adesso che la funzione è registrata posso usarla in una query sql, nel formato Scala
df.selectExpr("power2(num)").show(5)
//posso usare la funzione anche nel formato SQL
//prima creiamo una view temporanea
df.createOrReplaceTempView("udfExampleSQL3")
//e poi la query
spark.sql("SELECT power2(num) AS p2 FROM udfExampleSQL3").show(5)
+−−−+ |num| +−−−+ | 1| | 4| | 7| | 10| | 13| +−−−+ only showing top 5 rows +−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−+ |UDF:power2(cast(num as double))| +−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−+ | 1.0| | 16.0| | 49.0| | 100.0| | 169.0| +−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−+ only showing top 5 rows +−−−−−+ | p2| +−−−−−+ | 1.0| | 16.0| | 49.0| |100.0| |169.0| +−−−−−+ only showing top 5 rows df: org.apache.spark.sql.DataFrame = [num: int]
DataFrameReader
Candidates are expected to know how to:
- Read data for the “core” data formats (CSV, JSON, JDBC, ORC, Parquet, text and tables)
In modo generico questo è il comando per leggere dati da una sorgente esterna in un dataframe:
spark.read.format("csv")
.option("mode", "FAILFAST")
.option("inferSchema", "true")
.option("path", "path/to/file(s)")
.schema(someSchema)
.load()
Una delle opzioni è il read mode, che specifica cosa fare in caso di dati malformati. Queste sono le possibilità:
- permissive (DEFAULT), Sets all fields to null when it encounters a corrupted record and places all corrupted records in a string column called _corrupt_record
- dropMalformed, non importa i dati malformati
- failfast, da un messaggio di errore ed interrompe la procedura di lettura
Questi sono i comandi per leggere i formati più comuni:
val dataFrame = spark.read.json("example.json")
val dataFrame = spark.read.csv("example.csv")
val dataFrame = spark.read.parquet("example.parquet")
val dataFrame = spark.read.text("file.txt")
val dataFrame = spark.read.orc("file.orc")
val dataFrame = spark.read.jdbc(url,"person",properties)
Per i dettagli riguardo il connettere Spark ad un database SQL usando jdbc si può fare riferimento a questo link
Una sintassi equivalente per importare i file è la seguente:
spark.read.format("json").load("example.json")
spark.read.format("csv").load("example.csv")
spark.read.format("parquet").load("example.parquet")
spark.read.format("text").load("file.txt")
- How to configure options for specific formats
Devo usare il metodo option(“parametro”, “valore”), mettendo anche più option in cascata.
val df = spark.read.option("header", "true").option("inferSchema", "true").csv("exampl1.csv")
//or
val df2 = spark.read.options(Map(("header", "true"), ("inferSchema","true"))).csv("exampl1.csv")
//or
val df3 = spark.read.format("csv").option("header", "true").option("inferSchema", "true").option("mode", "FAILFAST").load("exampl1.csv")
df: org.apache.spark.sql.DataFrame = [eta: int, amici: int] df2: org.apache.spark.sql.DataFrame = [eta: int, amici: int] df3: org.apache.spark.sql.DataFrame = [eta: int, amici: int]
Per vedere le opzioni disponibili per i metodi di DataFrameReader, ad esempio csv, si può fare riferimento alla documentazione della API.
Ad esempio per conoscere tutte le opzioni disponibili per csv si può clikkare sulla freccia per espandere il campo csv (vedere la figura sotto).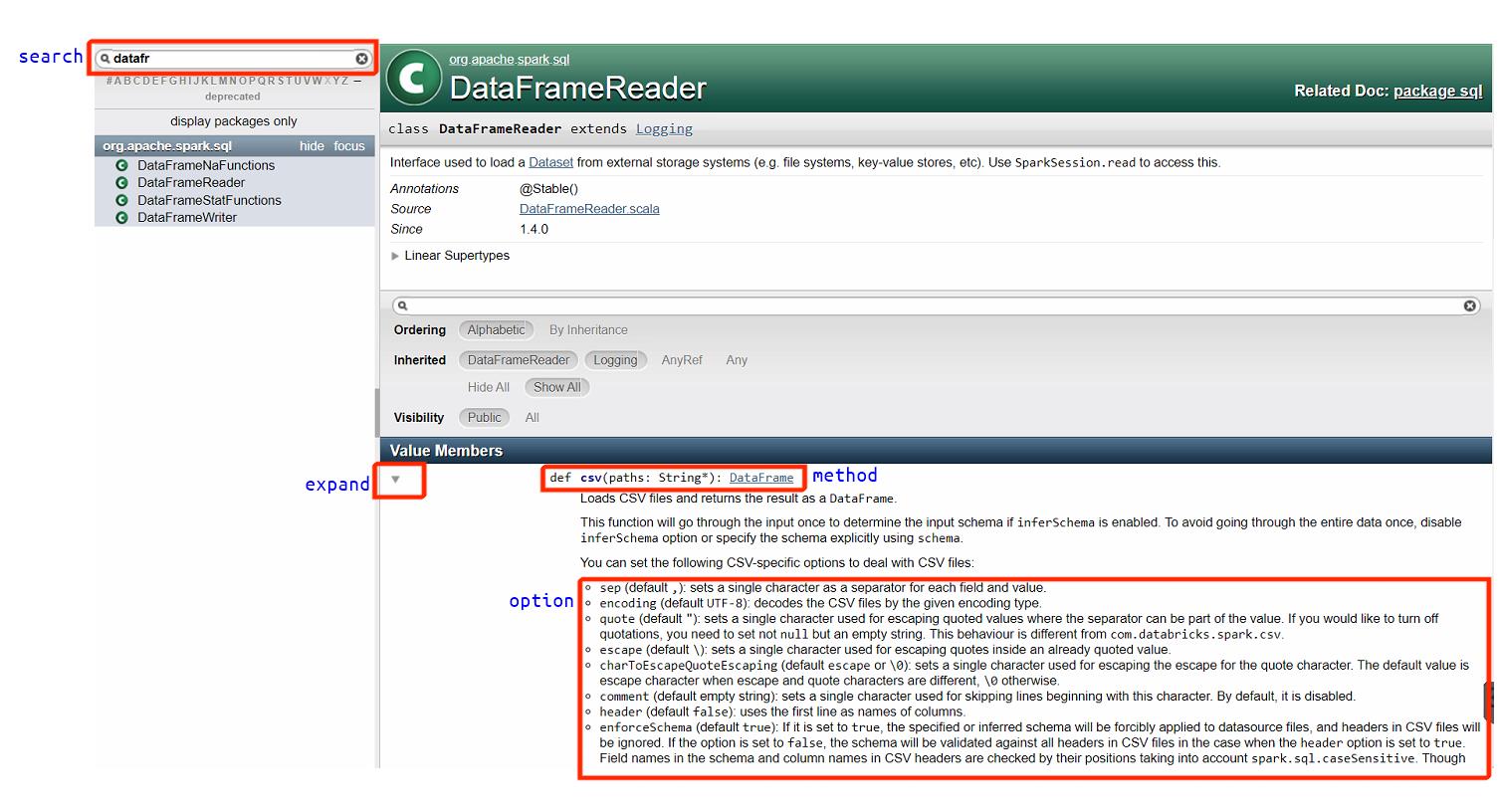
Alcune delle opzioni sono per l’importazione dei file csv sono:
– header
– inferSchema
– mode
– …
- How to read data from non-core formats using format() and load()
Supponiamo di avere un file in cui i dati sono salvati seguendo un formato particolare, per esempio:
– il separatore è il segno meno – invece della virgola ,
– nel file ci sono linee di commenti che iniziano con <!–
– il file è indentato per cui ci sono spazi vuoti all’inizio delle righe
– etc.
per ognuno di questi casi particolari trovo una opzione di load.
val df = spark.read.format("txt").option("sep","-").option("inferSchema","true").option("header","true").option("ignoreLeadingWhiteSpace","true").option("comment", "<!--").load(data_file)
- How to construct and specify a schema using the StructType classes
Come già visto in precedenza, dobbiamo importare StructType and StructField. E costruire lo schema come nel codice sottostante.
import org.apache.spark.sql.types.{StructType, StructField, StringType, IntegerType, FloatType}
val my_schema = StructType( List(
StructField("nome", StringType),
StructField("cognome", StringType, nullable=true),
StructField("altezza", IntegerType, nullable=true),
StructField("peso", FloatType, nullable=true),
StructField("età", IntegerType)
)
)
val df = spark.read.format("csv").schema(my_schema).option("mode","PERMISSIVE").load("exampl2.csv")
df.show()
+−−−−−−−−+−−−−−−−−−+−−−−−−−+−−−−+−−−+
| nome| cognome|altezza|peso|età|
+−−−−−−−−+−−−−−−−−−+−−−−−−−+−−−−+−−−+
| Pippo| Paolini| 167|72.3| 44|
| Luigi| Russo| 178|89.2| 5|
|Giovanna| Rosso| 175|80.0| 44|
|Giuseppe| Bianchi| 165|75.8| 9|
| Amedeo| Verdi| 167|56.2| 18|
| Luisa|Valentino| 182|64.9| 15|
+−−−−−−−−+−−−−−−−−−+−−−−−−−+−−−−+−−−+
import org.apache.spark.sql.types.{StructType, StructField, StringType, IntegerType, FloatType}
my_schema: org.apache.spark.sql.types.StructType = StructType(StructField(nome,StringType,true), StructField(cognome,StringType,true), StructField(altezza,IntegerType,true), StructField(peso,FloatType,true), StructField(età,IntegerType,true))
df: org.apache.spark.sql.DataFrame = [nome: string, cognome: string ... 3 more fields]
- How to specify a DDL-formatted schema
il metodo schema del DataFrameReader consente di specificare lo schema dei dati usando un formato DDL. Per esempio:
spark.read.schema("a INT, b STRING, c DOUBLE").csv("test.csv")
DataFrameWriter
- Write data to the “core” data formats (csv, json, jdbc, orc, parquet, text and tables)
Il modo generico di usare il DataFrameWriter è:
DataFrameWriter.format(...).option(...).partitionBy(...).bucketBy(...).sortBy(...).save()
il formato di default è parquet.
Queste sono le varie possibilità:
df.write.parquet(folder-path) df.write.orc(folder-path) df.write.json(folder-path) df.write.csv(folder-path) df.write.text(folder-path)
Scrivere un file csv
Esempio scrittura file tsv (tab separated values):
df.write.format("csv").mode("overwrite").option("sep", "\t").save("/my-tsv-file.tsv")
Salvare una tabella
Con saveAsTable() il dataframe viene salvato nelle tabella specificata. La tabella sarà pertanto disponibile in catalog e verrà salvata nell’hive metastore (di default la cartella spark-warehouse).
df.write.saveAsTable("mytable")
Scrivere un json file
Si noti che il numero di file creati è pari al numero di partizioni del dataframe.
// df.write.json(folder-path)
// oppure
val df = (1 to 10).toDF()
df.write.format("json").save("d:\\AnacondaProjects\\testSave")
df: org.apache.spark.sql.DataFrame = [value: int]
- Overwriting existing files
Possiamo usare il metodo mode del DataFrameWriter, per indicare cosa fare in caso di file esistenti, per esempio
df.write.mode("append").csv("data.csv")
.mode() definisce cosa fare nel caso in cui dati con lo stesso nome son già presenti nella locazione specificata. Le opzioni disponibile sono:
– overwrite sovrascrive i dati
– append appende i dati
– ignore ignora
– error default, da un errore nel runtime
- How to configure options for specific formats
Opzioni per la srittura di un csv file
Le opzioni per esportare un file in csv sono al link
Qui sotto riportate:
- sep (default ,): sets a single character as a separator for each field and value.
- quote (default “): sets a single character used for escaping quoted values where the separator can be part of the value. If an empty string is set, it uses u0000 (null character).
- escape (default ): sets a single character used for escaping quotes inside an already quoted value.
- charToEscapeQuoteEscaping (default escape or \0): sets a single character used for escaping the escape for the quote character. The default value is escape character when escape and quote characters are different, \0 otherwise.
- escapeQuotes (default true): a flag indicating whether values containing quotes should always be enclosed in quotes. Default is to escape all values containing a quote character.
- quoteAll (default false): a flag indicating whether all values should always be enclosed in quotes. Default is to only escape values containing a quote character.-
- header (default false): writes the names of columns as the first line.
- nullValue (default empty string): sets the string representation of a null value.
- emptyValue (default “”): sets the string representation of an empty value.
- encoding (by default it is not set): specifies encoding (charset) of saved csv files. If it is not set, the UTF-8 charset will be used.
- compression (default null): compression codec to use when saving to file. This can be one of the known case-insensitive shorten names (none, bzip2, gzip, lz4, snappy and deflate).
- dateFormat (default yyyy-MM-dd): sets the string that indicates a date format. Custom date formats follow the formats at java.text.SimpleDateFormat. This applies to date type.
- timestampFormat (default yyyy-MM-dd’T’HH:mm:ss.SSSXXX): sets the string that indicates a timestamp format. Custom date formats follow the formats at java.text.SimpleDateFormat. This applies to timestamp type.
- ignoreLeadingWhiteSpace (default true): a flag indicating whether or not leading whitespaces from values being written should be skipped.
- ignoreTrailingWhiteSpace (default true): a flag indicating defines whether or not trailing whitespaces from values being written should be skipped.
csvFile.write.format("csv").mode("overwrite").option("sep", "\t").save("my-tsv-file.tsv")
df.write.option("sep", ",")
.option("quote", "U+005C")
.option("escape", "U+005C")
.option("charToEscapeQuoteEscaping", "\0")
.option("escapeQuotes", "true")
.option("quoteAll", false)
...
Opzioni per la scrittura di un file json
Posso settare i seguenti parametri:
– compression (default null): definisce l’algoritmo di compressione usato per salvare il file. Si può scegliere tra: none, bzip2, gzip, lz4, snappy and deflate.
– dateFormat (default yyyy-MM-dd): setta la stringa che definisce il tipo data. I formati per la data sono indicati in java.text.SimpleDateFormat.
– timestampFormat (default yyyy-MM-dd’T’HH:mm:ss.SSSXXX): setta la stringa che indica il timestampFormat. I formati per il timestamp sono indicati in java.text.SimpleDateFormat.
- How to write a data source to 1 single file or N separate files
Di default Spark salva un numero di files pari al numero di partizioni in cui i dati sono divisi. Se voglio cambiare il numero di files generati devo usare i metodi .coalesce() e .repartition() per modificare il numero di partizioni del dataframe originario.
df.coalesce(1).write.csv("D:\\Anacondaprojects\\prova")
df.repartition(10).write.csv("D:\\Anacondaprojects\\prova2")
- How to write partitioned data
In alternativa, per dividere il file in files più piccoli posso usare il metodo partitionBy(“colonna”).
In questo modo per ogni valore (key) della colonna passata come parametro viene generata una cartella dentro la quale viene salvato il file contenente tutti i dati relativi solo alla key corrente, nel formato desiderato, per esempio csv.
df.write.partitionBy("country").csv("./folder1")
- How to bucket data by a given set of columns
Il bucketing è una tecnica che usa i buckets (contenitori) per definire il partizionamento dei dati e ridurre lo shuffle dei dati stessi.
Si veda la pagina Bucketing su The internal of Spark SQL.
Nella pagina linkata è mostrato come facendo il join di due dataframe salvati con il metodo .bucketBy() ci si risparmia lo shuffle nell’operazione di join. Si noti che avendo salvato con bucketBy i dati sono pre-shuffled.
Per eseguire il bucketing devo indicare quanti file salvare e su quale colonna di dati fare il bucketing/partizionamento.